6 Tidying data with tidyr
6.1 Tidy data
Before you can start analysing or plotting data, you often need to tidy it.
Tidy data is a standardised way to structure a dataset which makes it much easier to process, analyse and plot the data.
Functions in the tidyr and dplyr packages, both part of tidyverse, can be very useful for tidying data.
In tidy data
- Every column is a variable.
- Every row is an observation.
- Every cell is a single value.
The process of tidying data is to convert the data you have to data that meets this standard.
6.2 separate() multiple values
If a cell contains multiple values, we can use tidyr::separate().
For example, in this small dataset, site code and plot number have been combined into one column separated by a hyphen.
dat <- tribble(~id, ~value,
"A-1", 1,
"A-2", 2,
"B-1", 3)
dat## # A tibble: 3 × 2
## id value
## <chr> <dbl>
## 1 A-1 1
## 2 A-2 2
## 3 B-1 3We can use separate() to split site and plot into separate columns.
By default, separate() splits the data at non-alphanumeric values.
This behaviour can be controlled with the sep argument.
## # A tibble: 3 × 3
## site plot value
## <chr> <chr> <dbl>
## 1 A 1 1
## 2 A 2 2
## 3 B 1 36.3 Reshaping data - wide to long
It is very common to need to reshape data to make it tidy.
This can be done with the pivot_* functions.
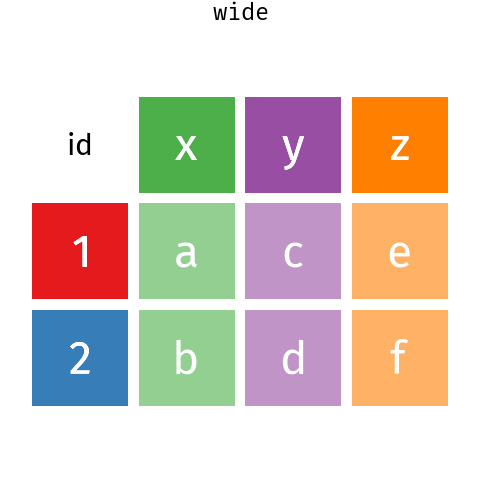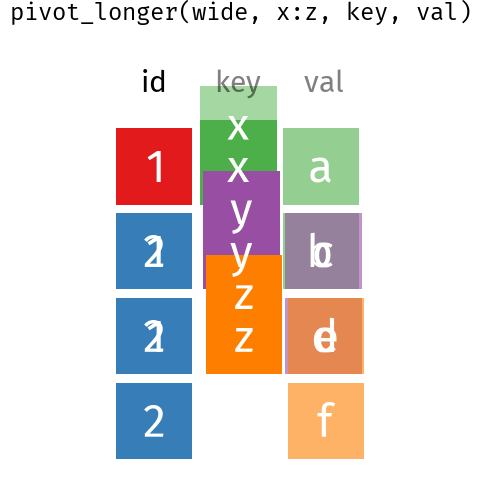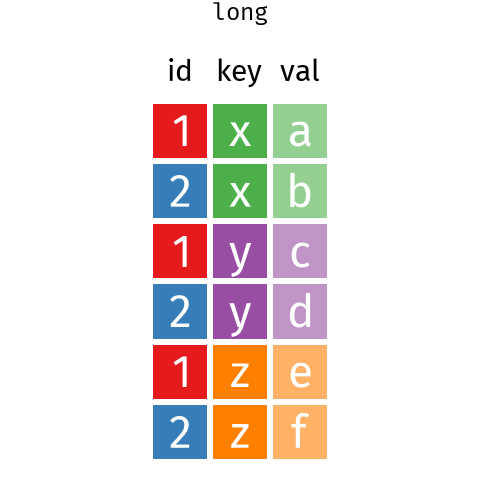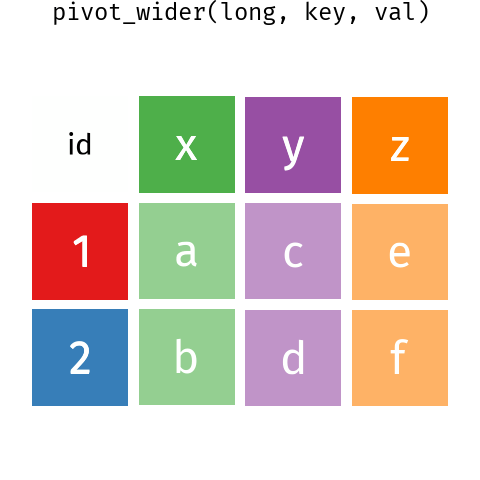
Figure 6.1: Wide data to long data with pivot_longer() and pivot_wider() .
These are some Bergen climate data from Wikipedia (NB for demonstration only wikipedia is not a good source of climate data - use seklima for Norwegian data).
## Rows: 4 Columns: 13## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (1): Måned
## dbl (12): Jan, Feb, Mar, Apr, Mai, Jun, Jul, Aug, Sep, Okt, Nov, Des##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 4 × 13
## Måned Jan Feb Mar Apr Mai Jun Jul Aug Sep Okt Nov Des
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Norma… 3.6 4 5.9 9.1 14 16.8 17.6 17.4 14.2 11.2 6.9 4.7
## 2 Døgnm… 1.7 1.7 3.3 5.8 10.4 13.1 14.2 14.2 11.5 8.8 4.8 2.7
## 3 Norma… -0.4 -0.5 0.9 3 7.2 10.2 11.5 11.6 9.1 6.6 2.8 0.6
## 4 Nedbø… 190 152 170 114 106 132 148 190 283 271 259 235This might be a nice way to present the data but it is not tidy data: each row is not an observation; each column is not a variable.
We can use pivot_longer() to reshape the data.
The months, selected by the cols argument in the column names (see section 7.2.1 for more on the syntax used here) will become a new variable with a name set by the names_to, and the data values get put into a column named by the values_to argument.
bergen_klima_long <- bergen_klima |>
pivot_longer(cols = Jan:Des, names_to = "Month", values_to = "value")
bergen_klima_long## # A tibble: 48 × 3
## Måned Month value
## <chr> <chr> <dbl>
## 1 Normal maks. temp. °C Jan 3.6
## 2 Normal maks. temp. °C Feb 4
## 3 Normal maks. temp. °C Mar 5.9
## # … with 45 more rowsThe data are now tidier, but it would probably be more useful to reshape the data again, and have a column for each climate variable.
We can do this pivot_wider().
6.4 Reshaping data - long to wide
We can tell pivot_wider() which column contains what will become the column names and the data with the names_from and values_from, respectively.
bergen_klima_wider <- bergen_klima_long |>
pivot_wider(names_from = "Måned", values_from = "value")
bergen_klima_wider## # A tibble: 12 × 5
## Month `Normal maks. temp… `Døgnmiddeltemp. … `Normal min. temp… `Nedbør (mm)`
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Jan 3.6 1.7 -0.4 190
## 2 Feb 4 1.7 -0.5 152
## 3 Mar 5.9 3.3 0.9 170
## 4 Apr 9.1 5.8 3 114
## 5 Mai 14 10.4 7.2 106
## 6 Jun 16.8 13.1 10.2 132
## 7 Jul 17.6 14.2 11.5 148
## 8 Aug 17.4 14.2 11.6 190
## 9 Sep 14.2 11.5 9.1 283
## 10 Okt 11.2 8.8 6.6 271
## 11 Nov 6.9 4.8 2.8 259
## 12 Des 4.7 2.7 0.6 235The data are now in a convenient format for plotting or analysis.
Exercise
With the Mt Gonga data downloaded previously, pivot the data so that the height data (H1-H10) are in one column.
Hint
pivot_longer